- Spotify started with a few Hadoop servers, and this cluster grew to +2000 nodes. Because the company wanted to focus on serving music, rather than operating data centres, they started moving to Google Cloud.
- While users are producing +50 TB of data daily, analysts and developers are producing +60 TB of data daily. This data is used for things like reporting and feature usage.
- Teams are autonomous and can choose which datasets their services ingest and output. This leads to a complex graph of dependencies, and +4000 individual Hadoop data jobs.
- Eventually, Spotify had to deal with a “Summer of incidents” in 2015 that brought Hadoop to its knees. A tedious amount of manual fixing, and re-running of jobs was needed.
- A few things needed to change. Datamon was built for data monitoring, to provide early warning. Styx was built for better scheduling, control, and debuggability of jobs, and GABO was built for event delivery, and to automate capacity.
- Datamon: The main problems that were identified after the incidents were the lack of clear data ownership, SLA on late data, and a unified view of data between different teams.
- These problems were tackled by defining clear data terminology, providing a metadata language, and implementing the Datamon service.
- Styx (a better cron) solves the problems of data jobs execution control in a self-serving way for teams, providing debugging information about them and executing them in an isolated way, using Docker and Kubernetes.
- GABO: Spotify replaced a complex Kafka setup with GCP’s PubSub and Dataflow streaming. PubSub was able to scale without issues, but Dataflow streaming couldn’t handle deduplicating large datasets that couldn’t fit in memory. This was replaced with 2 microservices and 1 Map/Reduce job. GABO was built to automate all this configuring and provisioning without requiring engineering time.
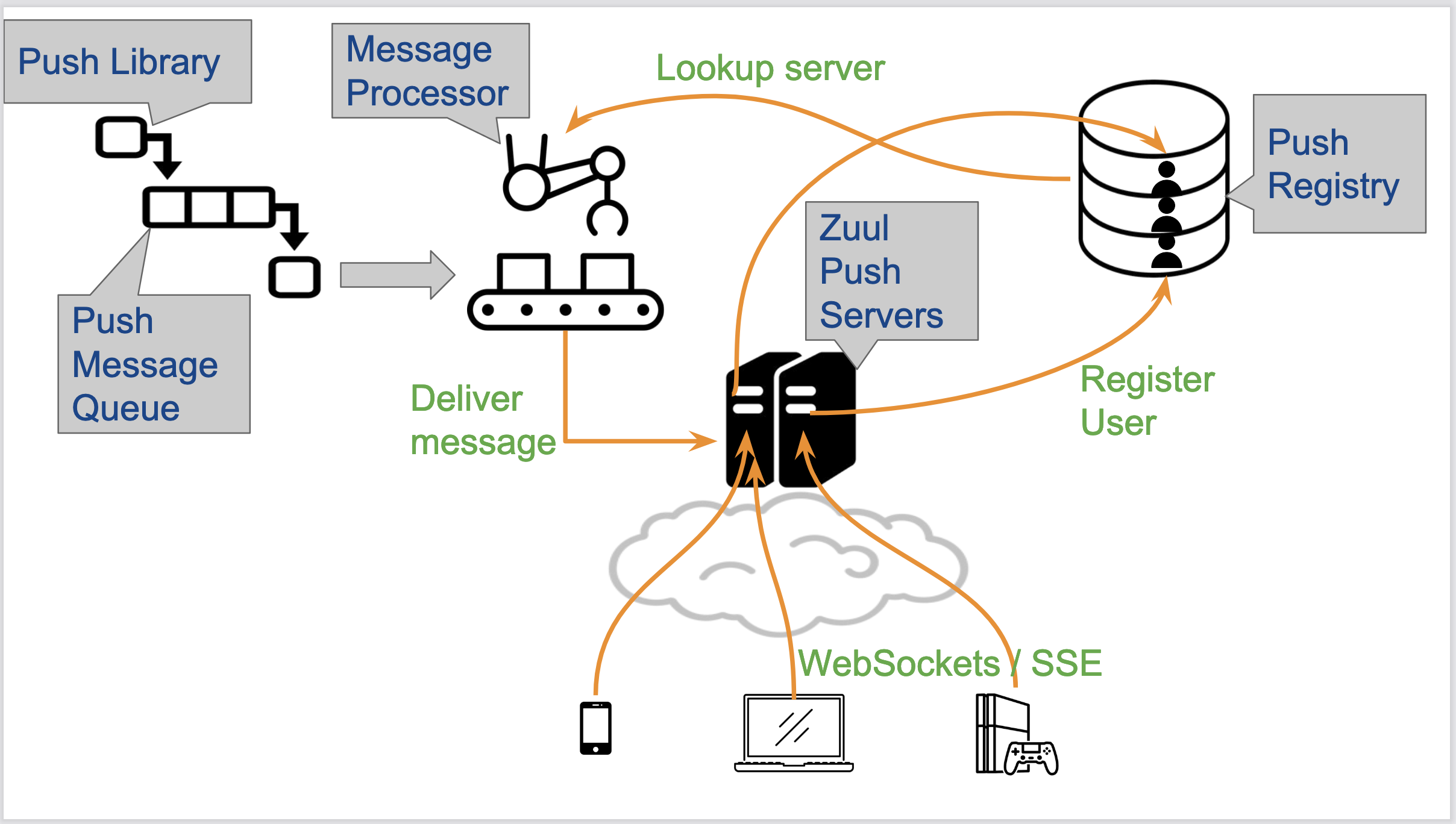
- Earlier versions of Netflix used to routinely pull the list of recommendations. Switching to a push architecture reduced the number of requests handled by the servers by ~12%.
- Users connect to the Zuul Push Servers via Websocket/SSE. The Push Registry tracks which users are connected to which servers.
- The Push library provides internal clients with the ability to send push notifications to users, knowing only the user ID. The Push Message Queue allows decoupling these internal clients from message delivery logic.
- The traditional way of creating one thread per connection doesn’t scale (due to context switching, and allocating memory/stacks for each new, often inactive, connection). Async I/O uses primitives like epoll() to register callbacks on the same thread. This is more scalable, but also more complicated, as you’ve to keep track of all these connection states.
- Zuul uses Netty library to abstract all this low-level connection handling, client authentication etc,.
- Push Registry: Requires low read latency, record expiry (as users don’t always disconnect cleanly), sharding for high availability, and replication for fault tolerance. Netflix uses Dynomite, a Redis-wrapper that adds features like read-write quorum and auto-sharding.
- Kafka is used a Message Queue. Multiple message processing instances are used to improve processing throughput.
- Persistent connections make your Push servers stateful, which is great for efficiency, but bad for deploys and rollbacks. This may lead to a thundering herd of re-connections from clients when a cluster is being updated.
- The solution is to close connections from the server-side periodically after a few tens of minutes, to still preserve client efficiency. Randomizing each connection’s lifetime improves this further, and leads to fewer simultaneous client re-connections.
- If the server initiates the TCP connection closing, it still has to keep the connection FD in a TCP TIME-WAIT state while waiting for the client to ack the close. A further optimization is for the clients to initiate the connection closing.
- Optimize for total server cost, not server count. Lower number of servers doesn’t necessarily mean more efficiency, especially when servers go down.
- RPS can’t be used for auto-scaling, as the number is too low (mostly inactive connections), and CPU is usually low. Number of open connections is a better metric.
- Amazon’s Elastic Load Balancer didn’t support WebSocket upgrade back then. Netflix had to run them in L4 (TCP) mode.
- To guarantee a client doesn’t lose a message when closing a connection, they can open a new connection beforehand. The last entry for the client in the Push Registry wins.

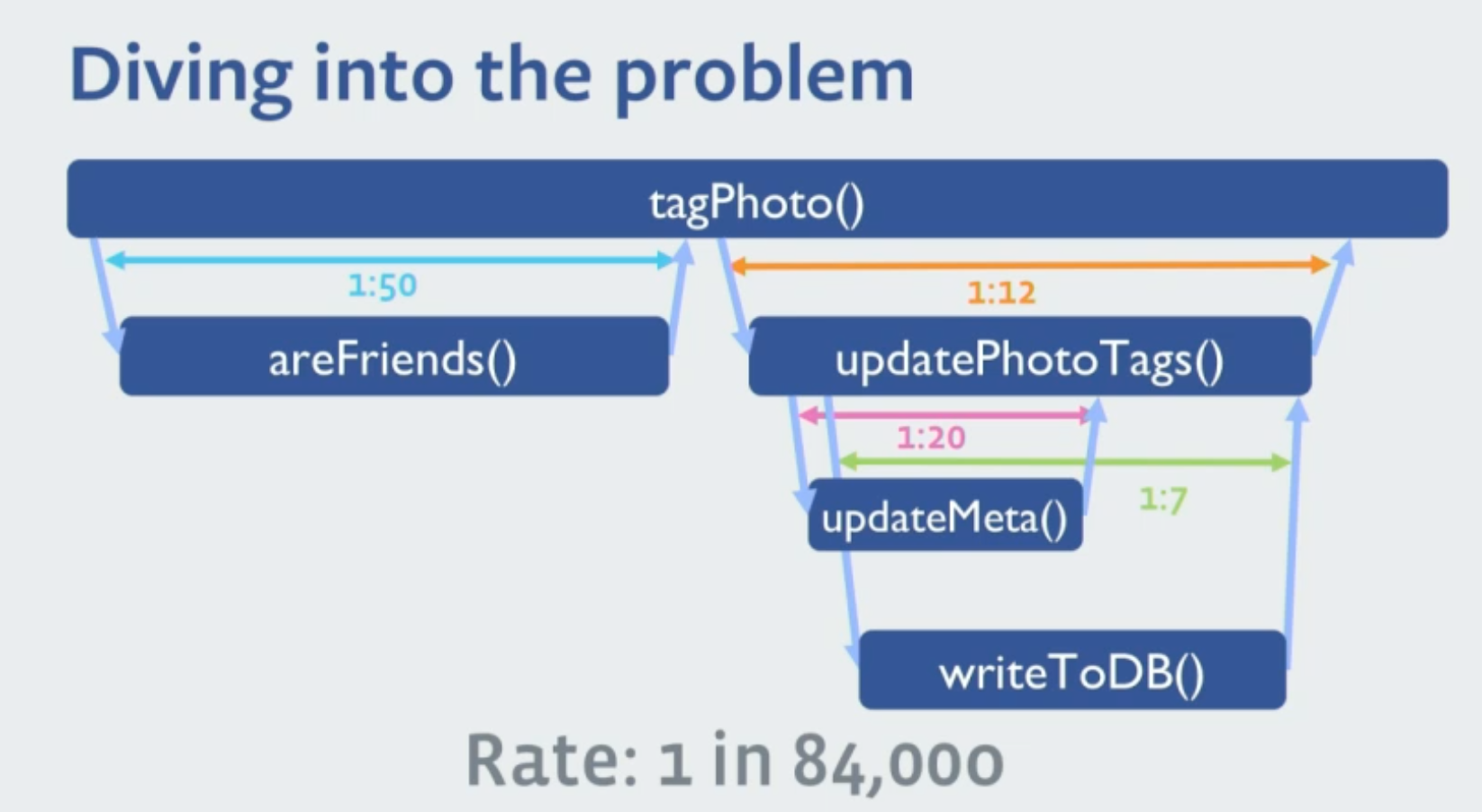
- A Microservices Architecture makes debugging problems harder. In a hypothesis-driven analysis, sampling of requests measurement makes it harder to have a full picture of what’s actually happening.
- Distributed Tracing collects information from multiple services and stores them in a single trace, in a tree form. The initial service generates a tag, that is further passed to other services in the request path. Each service sends its tracing information independently to the store, in order to not bloat the request/response.
- You don’t have to capture traces for every request. As most services are handling significant enough RPS, sampling is good enough. This saves bandwidth, storage and CPU resources.
- Sampling decision can be done at the start of request handling. The Sampling Engine allows assigning varying sampling rates based on request information (Host, endpoint…).
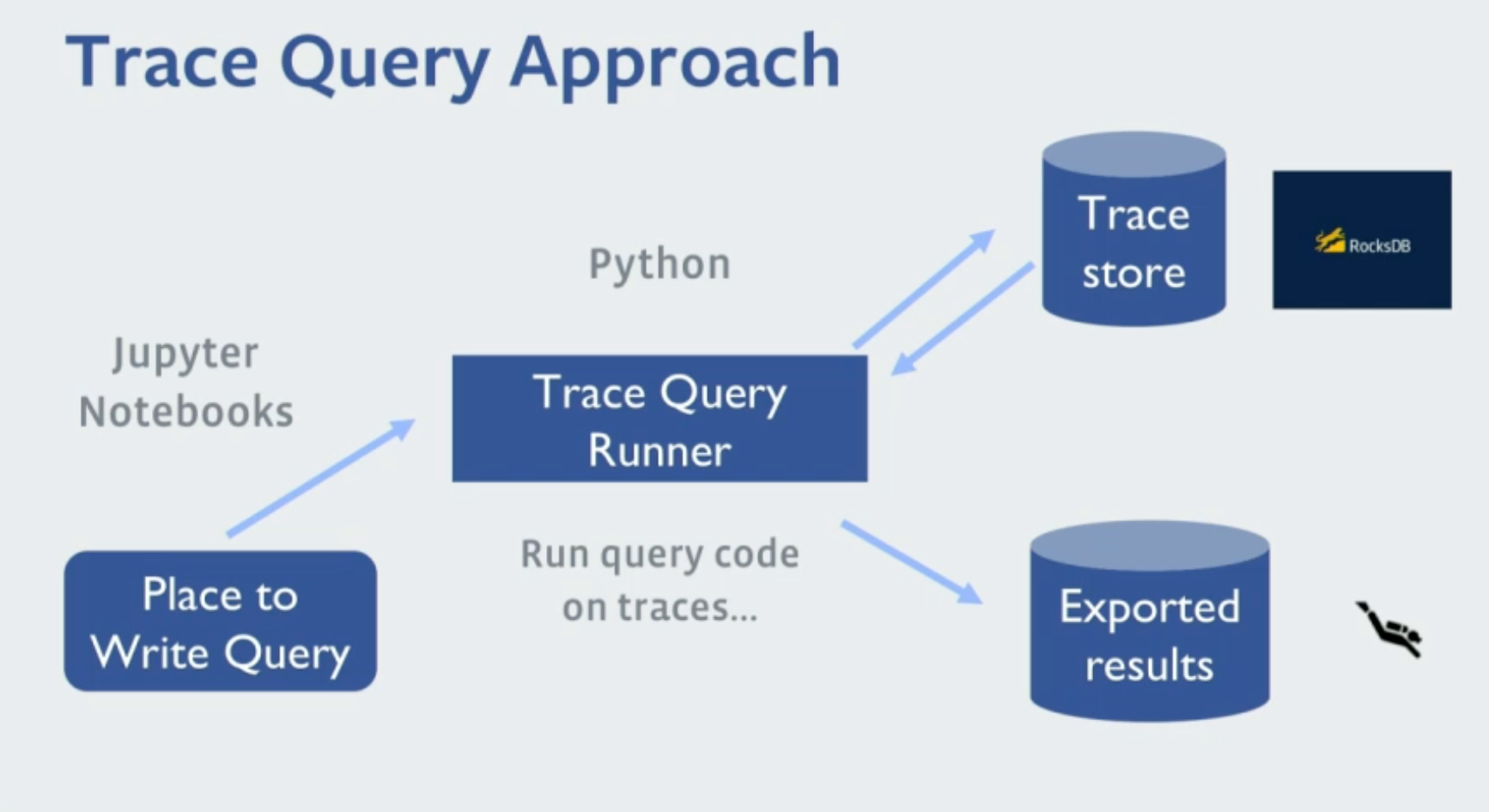
- The infrastructure at Facebook generates around 1 billion traces daily. It’s important to automate the analysis process, by developing a Trace Query runner that runs scripts on the Trace Store and exports the results.