Depth of Code
Hani’s blog
Book: Operating Systems - Three Easy Pieces

TLDR; 5/5. A very highly recommended reading!
Operating Systems: Three Easy Pieces (OSTEP) is a freely-available online textbook. At around +700 pages, this was certainly a lengthy read. Surprisingly, it was easy to digest and well worth the investment, confirming the great reviews that I’ve seen on Hacker News.
What I did like the most about this book is the iterative approach where a problem is tackled multiple times, starting with a naive approach, outlining its issues and explaining improvements and trade-offs until a satisfying solution is reached, while linking to relevant research papers that are out of the book’s scoop.
The chapters on Distributed Systems were a nice addition, more so because I was still actively interviewing back when I was going through the book, and they certainly helped with some system design interviews.
The only parts that I found lacking were the “simulation homeworks” which incurred more efforts than they were worth IMO.
Below is a summary in bullet points of the various ideas and topics discussed in the book.
Part 1: Virtualization (CPU)
- The abstraction of a running program as a process, the data structures used to track its information, and the different states (running, ready, blocked) it can be in.
- Some process-creation related APIs (fork(), wait(), exec() etc,.)
- Seamlessly sharing the CPU between different processes, how context switching works between different CPU modes, and the gaps of a Limited Direct Execution approach.
- The basic ideas behind job scheduling, the trade-offs of optimizing for turnaround time vs response time and the different scheduling approaches (FIFO, Shortest Job First, Round Robin, Shortest Time-to-Completion First…)
- The Multi-level Feedback Queue scheduler, which attempts to optimize for turnaround and response times by observing the behaviour of a job and adapting accordingly.
- Proportional-share (or fair-share) scheduling, which optimizes for jobs getting a certain amount of CPU time, using different approaches (lottery, stride, Linux CFS.)
- The different approaches related to multiprocessor scheduling (Single-queue, Multi-Queue.) The later is better at handling cache-affinity, but has issues related to load-imbalance and implementation complexity.
Part 1: Virtualization (Memory)
- An introduction to Virtual Memory, the differences between the stack and the heap and some of the memory allocation APIs on Linux.
- How simple hardware-based approaches like base-and-bounds and segmentation would work to achieve efficient and protected virtual-to-physical address translation. These are not flexible enough, and cause internal and external memory fragmentation issues.
- Common techniques used in memory allocators such as coalescing and splitting, and the different strategies used for managing free space (best fit, worst fit, buddy allocator…)
- The advantages of memory paging over previously discussed approaches (no external fragmentation, flexible use of sparse virtual address space…) and the content of page table entries (valid bit, r/w bit, present bit etc,.)
- Using hardware caching (Translation-Lookaside Buffer) to speed-up the virtual-to-physical address translations. The TLB may allow entries to include an address-space identifier (usually the PID) to preserve the entries between context switches.
- Reducing the size of page tables by splitting them into multi-level tables. A different approach uses inverted page tables, mapping physical pages to the process using this page.
- Leveraging disk storage for memory pages swapping. Page faults are generated by the CPU and handled by the OS to bring the pages back into RAM.
- The different policies used to decide which pages to swap out of memory (FIFO, Random, LRU, Approximative LRU etc,.)
- An overview of the VAX/VMS and Linux Virtual Memory systems.
Part 2: Concurrency
- Introduction to multithreading, the pthreads API and related topics such as race conditions, locks and condition variables.
- The criteria used to evaluate locks (mutual exclusion, fairness and performance.) Different old and modern approaches and primitives are used to implement locks: spinning, Test-and-Set, Compare-And-Swap, Fetch-and-Add, yielding and sleeping queues.
- How to build concurrent data structures such as lists and queues using locks.
- Condition variables and how to correctly use them to tackle producer/consumer problems.
- How to implement and use semaphores instead of locks and condition variables to model different concurrency problems.
- A showcase of various concurrency problems such as atomicity-violation, order-violation and deadlocks.
- An introduction to event-based concurrency, APIs such as select() and epoll() and using asynchronous I/O to handle blocking system calls.
Part 3: Persistence
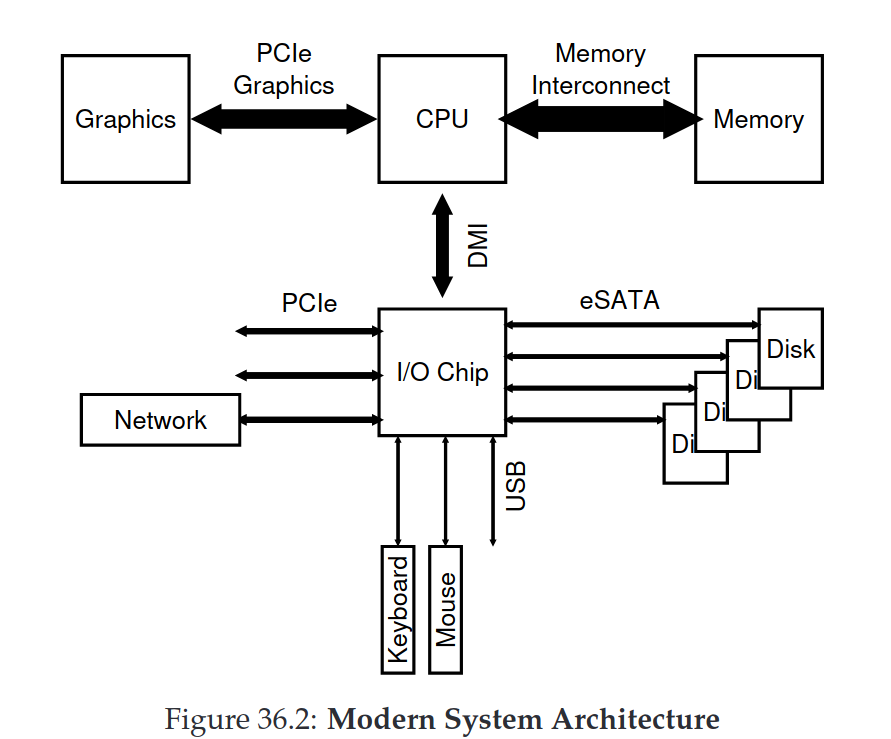
- Introduction to modern systems architecture and how the OS interacts with I/O devices through interrupts and DMA.
- The internals of Hard Disk Drives, and the different disk scheduling techniques (Shortest Seek Time First, SCAN, C-SCAN etc,.)
- Improving capacity and reliability of independent disks through RAID, and how different RAID levels compare in terms of redundancy and sequential/random reading and writing throughput and latency.
- The UNIX file system interface and the system calls involved in various tasks related files and directories (open(), unlink(), lseek()…)
- The implementation of a simple file system, its overall structure and the data structures used to track information such as superblocks, inodes and inodes and data block bitmaps. Also discussed are the challenges related to reducing I/O cost and improving caching and buffering.
- How to better organize file system data structures to improve performance. The Fast File System does so by being disk aware and keeping related data such as a file’s inode and its content in the same block groups.
- The two approaches used to solve the crash-consistency problem: file system checkers such as fsck and write-ahead logging (or journaling) as in ext3 and other modern file systems.
- The major ideas behind the Log-structured File System: Sequential disk writes instead of overwriting files in place, write buffering and keeping track of on-disk inodes through an inode map and a checkpoint region. Instead of cleaning the leftover garbage, NetApp’s WAFL transforms it into a file recovery feature.
- The structure of Flash-based SSDs, the differences related to reading and writing and the challenges related to performance and reliability. Wear leveling is the process of spreading writes to different blocks and migrating frequently read data to other blocks.
- There are two disk failure modes: Latent Sector Errors are recovered from through redundancy solutions such as RAID. Block corruption on the other hand is detected through different checksum functions.
Part 3: Distributed Systems
- A short introduction to communication protocols: UDP vs TCP and RPC.
- The focus of Sun’s Network File System on simplicity and fast crash recovery. Statelessness in NFS is achieved by ensuring that all operations are idempotent. Performance is improved through client caching.
- Andrew File System’s focus on scale. Server interactions are minimized with whole-file caching and through a callback, the server informs the client when a file changes, solving the issue of cache consistency and constant polling. To reduce the high cost of path traversals, a File ID is used.